This home page is generated by GPT-5.5-xhigh.
*Equal contribution †Project lead #Corresponding authors
Tech Report, 2026
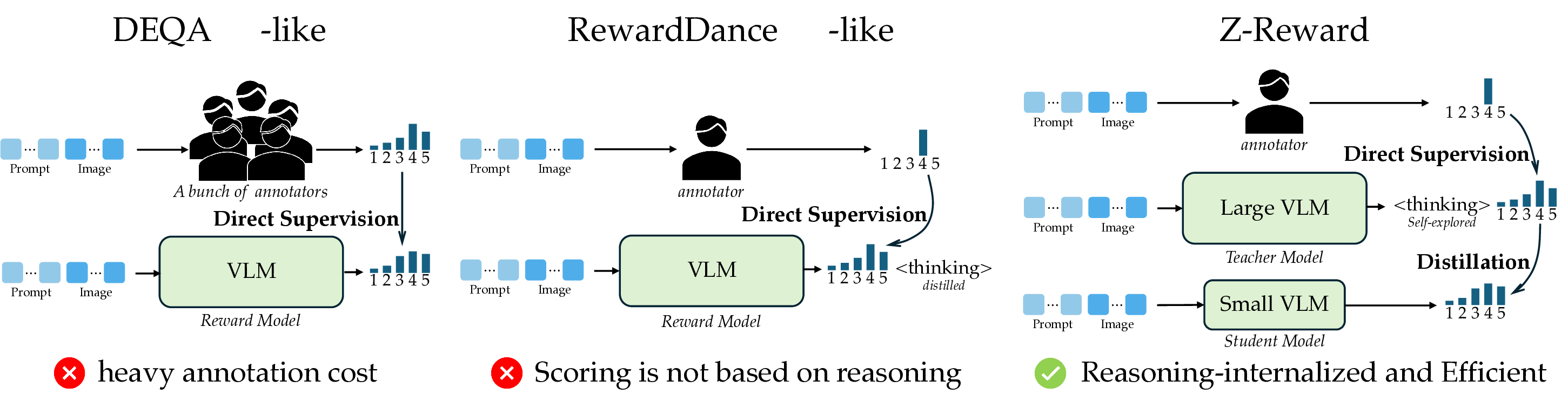
Reasoning-Internalized Reward Modeling
Scalar reward models compress subjective visual preference into a single number. Z-Reward instead learns rubric-aligned score distributions and transfers reasoning-heavy judgments from a large teacher VLM into a compact student VLM for efficient deployment.

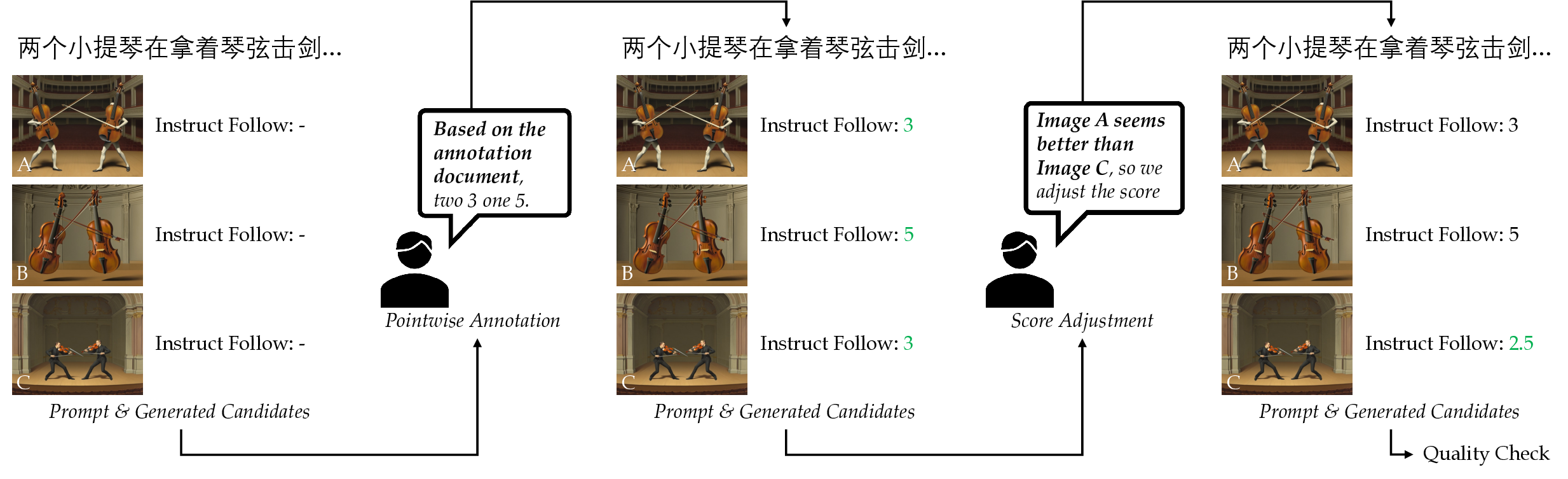
Pointwise Annotation with Score Adjustment
The annotation process first obtains rubric scores for generated candidates, then performs quality checks and score adjustment so the supervision better reflects relative image quality.
Stronger Teachers, Compact Students
The GDSO teacher improves preference accuracy through distributional supervision, and RISD transfers the teacher's reasoning-conditioned score distribution to a smaller model without explicit reasoning at inference time.
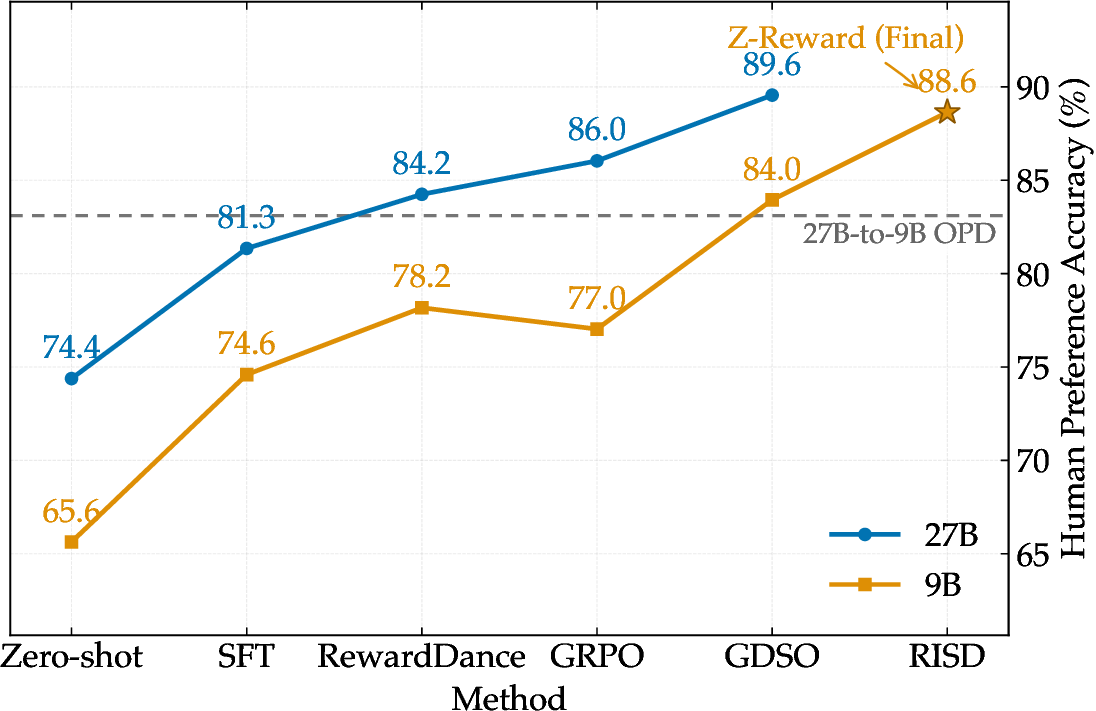
Method and model-size comparison.
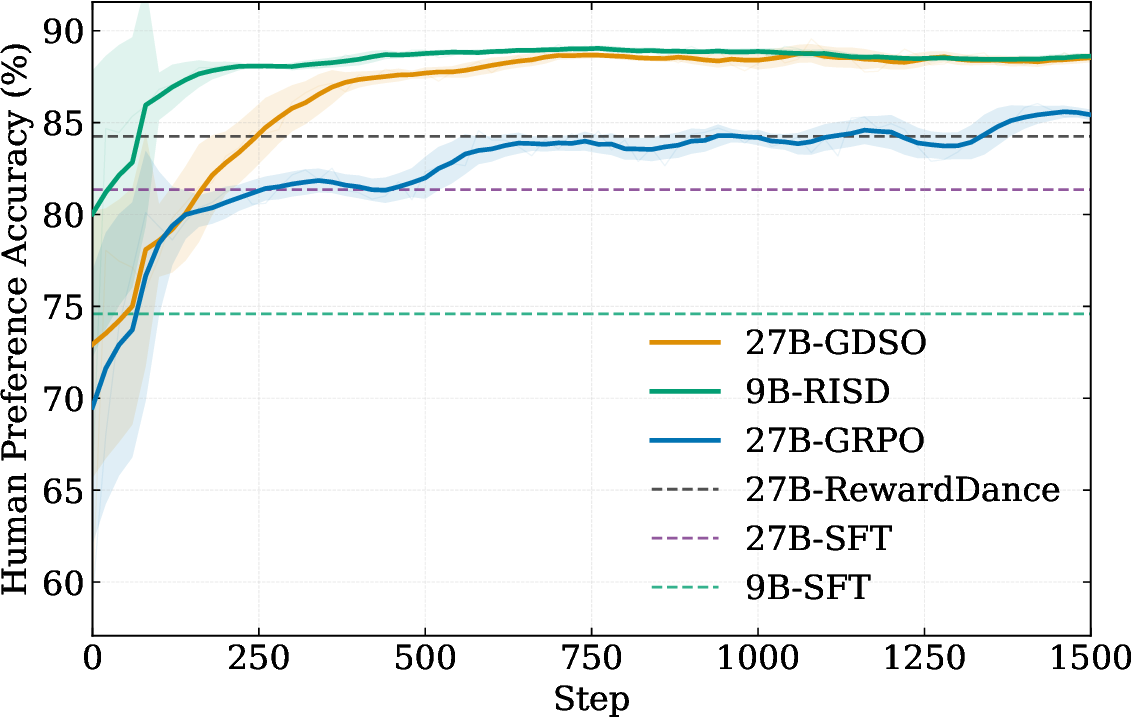
Training dynamics on human preference accuracy.
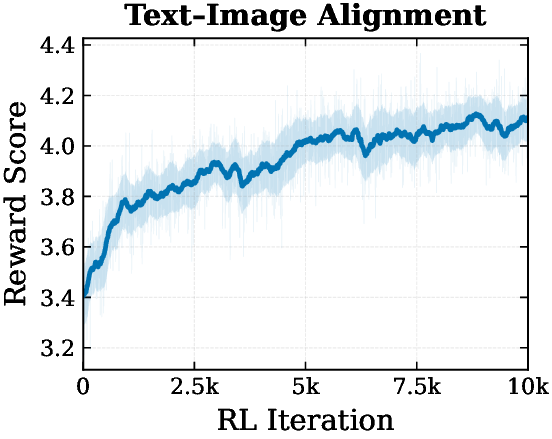
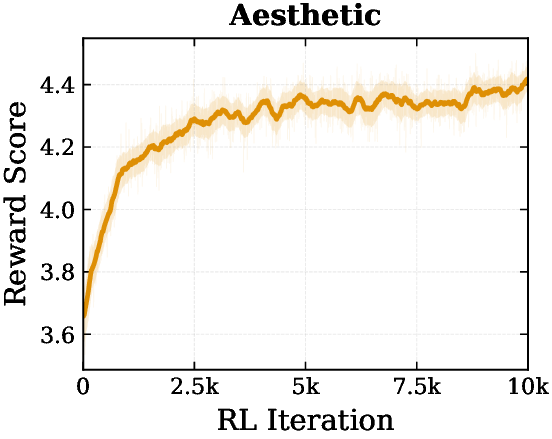
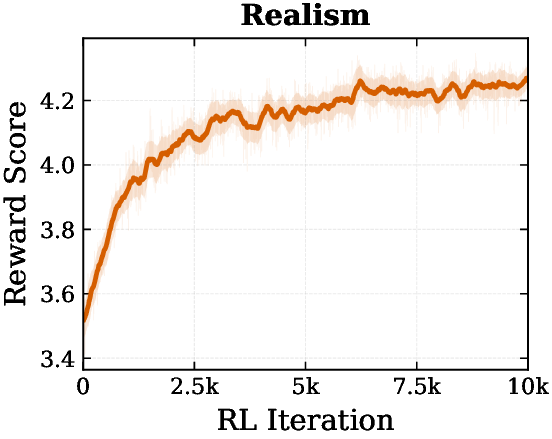
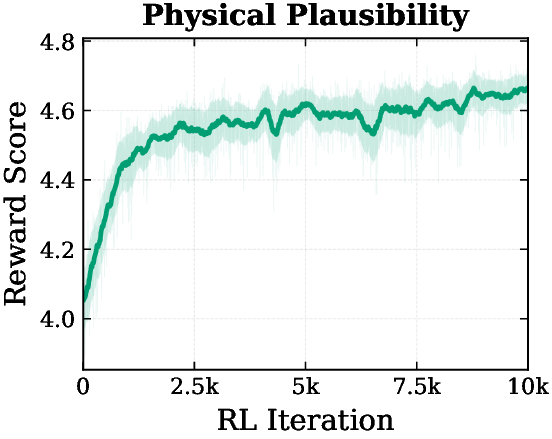
Reward-Guided Text-to-Image Optimization
Z-Reward can be used as a differentiable reward signal during text-to-image optimization. Across alignment, aesthetics, realism, and physical plausibility, reward scores steadily improve during RL.
Visual Examples
Reward-guided optimization improves prompt following, text rendering, and visual fidelity while preserving strong image composition.



BibTex
@article{jin2026beyond,
title={Beyond Scalar Rewards by Internalizing Reasoning into Score Distributions},
author={Jin, Xin and Cai, Huanqia and Li, Zhen and Zhan, Zechao and Jiang, Dengyang and Hao, Aiming and Jiang, Yuming and Guo, Chunle and Gao, Peng and Cheng, Ming-Ming and Hoi, Steven C.H.},
journal={arXiv preprint arXiv:2606.09076},
year={2026}
}Contact
Feel free to contact us at srameojin@gmail.com!